Interpreting math as code
When I took a year off from software engineering to study machine learning, one of my learning objectives was knowing how to convert equations from a textbook or paper into lines of code. I practiced coding math by implementing parts of machine learning concepts from scratch. Since graduating, I’ve continued writing these posts to help me review machine learning theory.
For example, I tried coding the sum-product algorithm, Gibbs sampling, and logistic regression. I’ve collected my machine learning concept demos here.
I think practicing how to interpret math as code was challenging and rewarding. I think it’s especially useful to do while learning machine learning foundations, so you both learn the foundations and learn how to interpret math as code. Here are a few tips to help you get started!
Find examples
Iain Murray’s course notes and Python code examples helped me learn how to get started translating math into code by showing examples (disclaimer: I took his course!)
David Barber’s Bayesian Reasoning and Machine Learning is another one of my favorites. The textbook includes implementation details (“use log here!”). The book also comes with MATLAB implementation that I can poke at if I get stuck.
Choose a broad topic that’s widely described
I typically start with a broad topic that I want to be more comfortable with, such as “KL Divergence.” You could also look for topics in cutting edge research papers, but I think it’s better to practice with widely-described concepts. In general, I choose topics that are explained in more than one of my machine learning textbooks. That way I can fall back on several sources’ (textbooks’, websites’, blogs’) explanations when I run into something unexpected.
Find one thing to implement
I try to keep the goal of the code small because I usually discover a few misconceptions that require some time for me to work through.
I think being able to visualize a concept is rewarding, so my goal is usually to reproduce a neat graph. The graphs usually require me to implement some key aspects of the topic. While briefly reviewing the topic, I try to find a graph that visualizes an important idea.
Usually, I end up producing intermediate and tangential graphs and code. Sometimes the target graph requires a lot of extra code, so I also might reduce the scope of the post to be about an intermediate graph instead.
As a few examples:
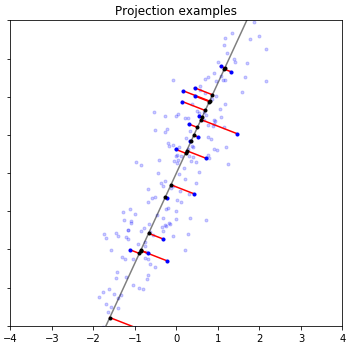 |
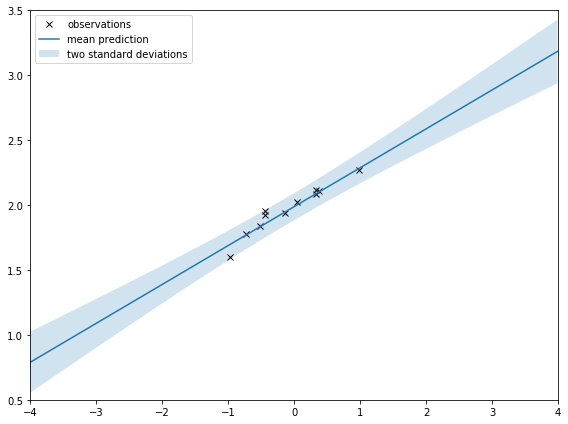 |
| How PCA reduces dimensions of data. | Gaussian Process regression with uncertainty. |
Make it easier to be correct while learning
Because I’m learning details while coding, it’s likely I’ll make mistakes. But because I publish all of the code of my demos, I want them to be mostly correct.
There are a few ways you can make it easier to know if you’re mostly correct: First, if you start with a graph from a textbook, you can check that your implementation outputs a similar graph on similar inputs. Sometimes you can even find numerical examples from textbooks.
Second generate your own data.
Generate your own noisy data
Keep things more obviously correct by generating your own noisy data points. If you’re trying to show a technique for learning an underlying function from noisy data (as a lot of machine learning is!), having control over the data’s underlying function means you can tell when it’s totally wrong.
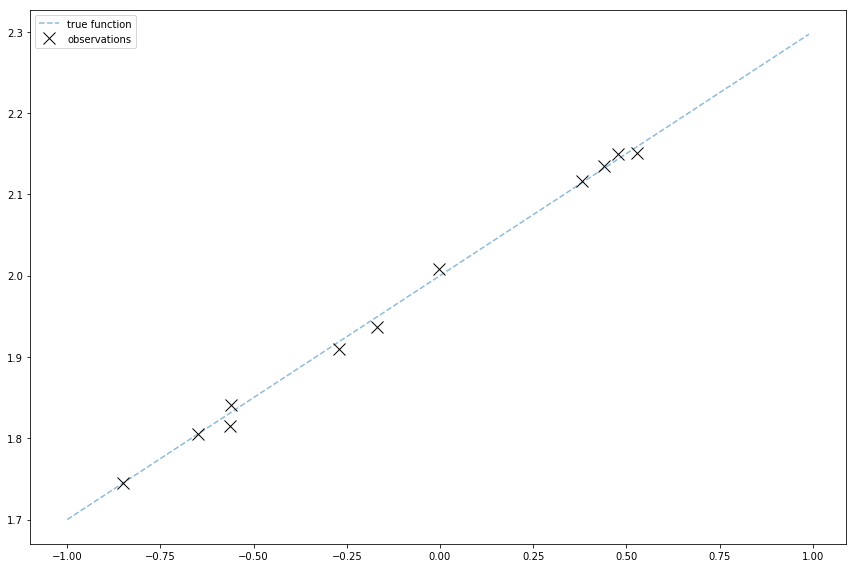
Use fewer dimensions
If it starts getting difficult, try reducing the number of dimensions.
I’ve done this for a lot of my posts! For example, I initially started my KL Divergence post with the goal of animating contour plots of 2D Gaussians. Since implementing multivariate Gaussian in TensorFlow was a little annoying and only tangentially related to KL Divergence, I dropped it and stuck with univariate Gaussians.
Be aware of the boundary of code and math
At the end of the day, machine learning typically needs to be written in code to deal with the large quantities of data. But sometimes the math equations aren’t intended to be converted directly into Python functions. For example, in Bayesian inference, if you use the right distributions, you can find an analytical solution that gives a simple formula to compute the posterior.
This is an area I should work on: because I feel more comfortable coding, I jump to coding early instead of trying to work through analytical solutions. For example, I ended up awkwardly use discrete distributions when demoing KL Divergence. Maybe if I worked through an analytical solution, I would have implemented it a different way.
Have fun!
I think implementing ML concepts in code is a good way to learn to interpret math as code and simultaneously learn the concepts. I hope these tips help you get started. Let me know how it goes!
See Also
- Another way to help learn machine learning concepts are note-taking and interactive widgets
- My machine learning concept demos!