KL Divergence
Machine learning involves approximating intractable probability distributions. One approach to approximating is to find a distribution that minimizes the KL Divergence with the target distribution. For example, the approximating distributions could be normal distributions with different means and variances.
When KL Divergence is introduced in the context of machine learning, one point is that KL Divergence \( KL(P \mid\mid Q) \) will select a different distribution than \( KL(Q \mid\mid P) \). This blog post explores this by telling an optimizer (TensorFlow) to minimize the two KL Divergences.

KL Divergence equation for discrete distributions
Wikipedia gives the KL Divergence for discrete distributions as
If \( P_i \) = 0, then the \( i^{th} \) term is 0. \( KL \) is only defined if when \( Q_i = 0 \), then \( P_i = 0 \).
For example, we can have \( P \) be the distribution we’re trying approximate with \( Q \). The KL Divergence will be big if \( Q_i \) is close to 0 where \( P_i \) is not close to 0. If \( P_i \) is close to 0, \( Q_i \) won’t affect the KL Divergence as much.
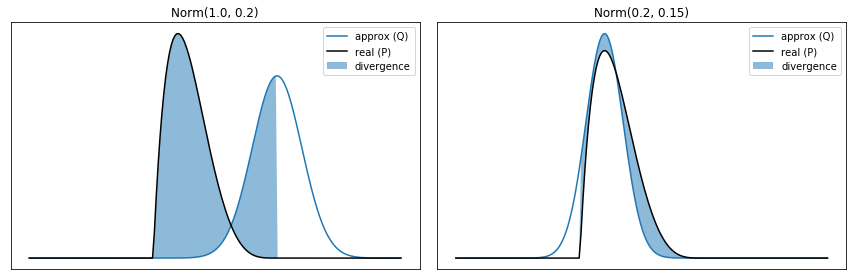
An example target distribution and two example approximate distributions
Let’s plot a few examples!
For this first example, I’ll make \( P \) based on the distribution \( \beta(2, 5) \). This is interesting because \( P_i \) is 0 outside of the domain of 0 to 1. I’ll use \( Q \)s that are based on a normal distribution, so \( Q \) is never 0. I highlight the area where \( P_i > 0 \).
Aside: Discrete vs Continuous
In order to make cool-looking graphs, I’m using discrete distributions that are based on continuous distributions, like the normal distribution. For example, below I start with 200 evenly-spaced numbers between -1 and 2. I compute the value of the PDF for those numbers. Then I normalize the vector so the 200 numbers add to 1 and it becomes a discrete distribution.
Computing KL Divergence
I can translate the formula to numpy, then compute the KL Divergence between the two approximating distributions and the target distribution.
As expected, the KL Divergence is higher for the approximating distribution based on Norm(1, 0.2) than the distribution based on Norm(0.2, 0.15).
def kl_divergence(p, q):
# Computes KL(p || q). Note that outside of this function, P is the target distribution
# and Q is the approximating distribution. Inside of this function, P is just the
# first argument and Q is the second.
# I inefficiently iterate through all of the q and p values to
# only compute the log when p_i > 0.
terms = [
p_i * np.log(p_i/q_i) if p_i > 0 else 0
for q_i, p_i in zip(q, p)
]
return np.sum(terms, axis=0)
print("Q = Norm(1.0, 0.20) \tKL(P || Q) = {:.6f}".format(
kl_divergence(p=real_dist, q=approx_dist_1),
))
print("Q = Norm(0.2, 0.15) \tKL(P || Q) = {:.6f}".format(
kl_divergence(p=real_dist, q=approx_dist_2)
))Q = Norm(1.0, 0.20) KL(P || Q) = 6.491177
Q = Norm(0.2, 0.15) KL(P || Q) = 0.236206
Aside: Verifying the implementation
scipy’s entropy computes KL Divergence when called with two parameters. I can verify my implementation produces similar results.
assert np.isclose(
kl_divergence(p=real_dist, q=approx_dist_1),
entropy(pk=real_dist, qk=approx_dist_1)
)
assert np.isclose(
kl_divergence(p=real_dist, q=approx_dist_2),
entropy(pk=real_dist, qk=approx_dist_2)
)Aside: Interactive
Before I implement something that minimizes the divergence automatically, I can use ipywidgets to interactively try different distributions.
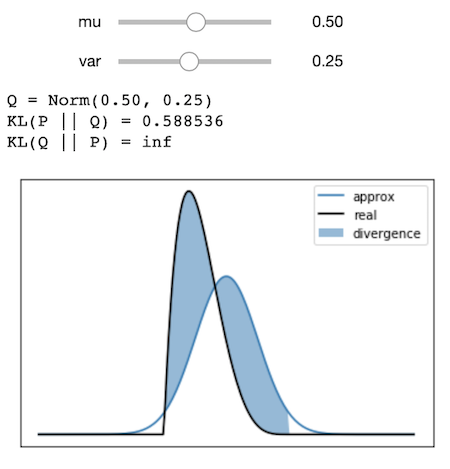
Multimodal Example
One point with KL Divergence is that finding a \( Q \) that minimizes \( KL(Q \mid\mid P) \) is different than finding a \( Q \) that minimizes \( KL(P \mid\mid Q) \). One way to illustrate the difference is to look at a multimodal distribution.
xgrid_multimodal = np.arange(-4, 4, 0.05)
real_dist_multimodal = norm(2, 0.3).pdf(xgrid_multimodal) + norm(-3, 0.3).pdf(xgrid_multimodal)
real_dist_multimodal /= np.sum(real_dist_multimodal, axis=0)
interact(
plot_and_compute_kl_divergence_for_real_dist(xgrid_multimodal, real_dist_multimodal),
mu=(-4, 4, 0.5),
var=(0.1, 10.0, 0.1)
) |
 |
Minimizing KL Divergence
I can implement KL Divergence in TensorFlow and then use gradient descent to find an approximating distribution \( Q = Norm(\mu, \sigma^2) \) that minimizes the KL Divergence.
def optimize_kl_divergence(bin_location, real_dist, iterations=100, learning_rate=0.05, find_kl_q_p=True):
D = 1 # This is only supported for 1-dimensional distributions.
# Placeholder for the true distribution
real_dist_placeholder = tf.placeholder(tf.float64, shape=(D, None))
# Set up variables for guess. This is what we'll learn.
approx_mu = tf.Variable(np.zeros(D))
approx_var = tf.Variable(np.eye(D))
# Convert mu and var into a discrete distribution
# We're normalizing it anyway, so we don't need the scaling coefficient
eq = tf.exp(-tf.square(bin_location - approx_mu) / (2 * approx_var))
approx_dist_op = eq / tf.reduce_sum(eq)
# Rewrite KL Divergence for TensorFlow
def tf_kl_divergence(q, p):
# This will give warnings because we're computing the log even when
# p is 0. But it uses values from the 0 array in that case.
terms = tf.where(p == 0, tf.zeros(real_dist.shape, tf.float64), p * tf.log(p/q))
return tf.reduce_sum(terms)
# This let's us switch whether we want the real distribution as Q or P.
if find_kl_q_p:
kl_div = tf_kl_divergence(p=approx_dist_op, q=real_dist_placeholder)
else:
kl_div = tf_kl_divergence(p=real_dist_placeholder, q=approx_dist_op)
loss_op = kl_div
# Learning rate is finicky!
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(loss_op)
# Now find an optimal mu and var that minimizes the KL divergence.
kl_divs = []
approx_dists = []
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(iterations):
approx_dist, loss, _, mu, var = sess.run(
[approx_dist_op, loss_op, train_op, approx_mu, approx_var],
{real_dist_placeholder: real_dist}
)
kl_divs.append(loss)
approx_dists.append(approx_dist)
return kl_divs, approx_dists, mu[0], var[0][0]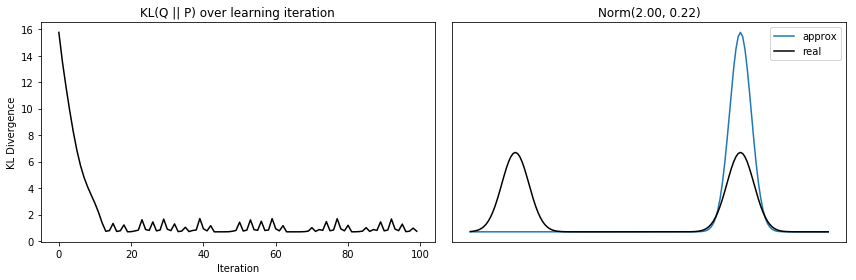
It’s also neat to plot how the distribution shifts as it improves!
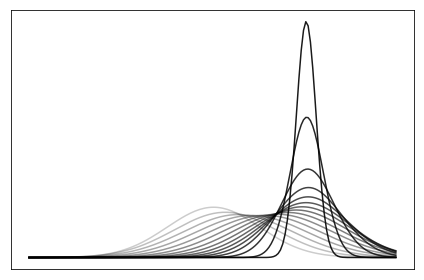
Comparison of KL(Q || P) to KL(P || Q)
Finally, I can compare the \( Q \) that minimizes \( KL(Q \mid\mid P) \) to the one that minimizes \( KL(P \mid\mid Q) \).
See Also
- Chapter 10 of Bishop’s PRML talks about Variational Inference and has examples using bimodal distributions over two dimensions.
- Another example of dealing with difficult distributions is using Gibbs Sampling!
- KL Divergence is used in Variational Methods like that used in Variational Inference, which is similar to Expectation-Maximization.