Learning Chernoff Faces
Chernoff faces are a creative way to visualize individual elements of multidimensional data. For example, a Chernoff face may be a cartoon face where one dimension of the data point determines the angle of the eyebrows and another determines the size of the eyes. Data points that are very different can produce very different faces and data points that are very similar produce similar faces.
 |
 |
|
The Chernoff faces make it easy for a human to notice patterns in smaller numbers of examples. Also I think Chernoff Faces are delightful and a little silly, which makes working with them a fun project.
Learning Chernoff faces and using them on embeddings
Producing Chernoff Faces requires a function that transforms a vector into a face. In this post, I’ll use an autoencoder to learn a function. And to test them out, I’ll convert my embeddings of library book subjects from a previous post into faces.

Training data
For the dataset, I used the labels from the Helen dataset, which includes annotated pictures of faces. Faces are represented by 194 coordinates that each correspond to a specific point of the face. For example, point 114 is the inner corner of the right eye.

To draw the faces, I connect some of the points. Below is a sample from the dataset.

Model
I’ll use a simple autoencoder to learn how to convert a multidimensional vector into a face. Specifically, the autoencoder will take the values that represent the face, learns an ‘encoder’ to map it onto 16 dimensions and a ‘decoder’ to map it back to the values representing the face. I optimize the network for trying to recreate the same face I pass in.
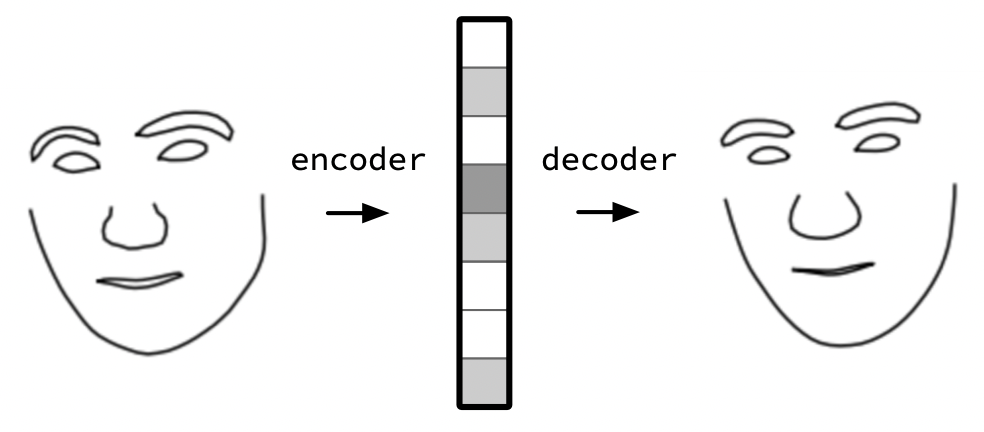
To learn the faces decoder, I was happy with the results produced using a very simple network defined in Keras below. I use one layer with a sigmoid activation function for the encoder and one layer for the decoder.
import keras
from keras.layers import Dense, Reshape, Flatten, Input
from keras.models import Model, Sequential
latent_dims = 16
img_shape = data[0].shape
img = Input(img_shape, name='img')
encoder = Sequential(name='encoder')
encoder.add(Flatten(name='encoder_flatten'))
encoder.add(Dense(latent_dims, activation='sigmoid', name='encoder_dense'))
encoder.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
decoder = Sequential(name='decoder')
decoder.add(Dense(np.prod(img_shape), name='decoder_dense'))
decoder.add(Reshape(img_shape, name='decoder_reshape'))
decoder.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
full = Model(img, decoder(encoder(img)), name='full')
full.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])full.fit(data, data, epochs=250)Fun with the autoencoder
encoded_faces = encoder.predict(data)Next I can test how well the model can encode and decode the faces. In the image below, the top row was input into the model and the bottom row was the corresponding output.
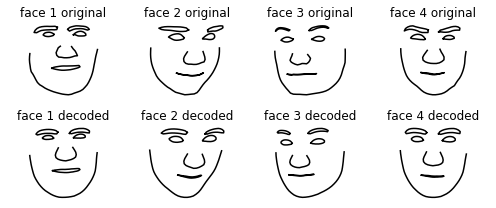
The output doesn’t match the input exactly. They tend to look more smooth and cartoonish, which is perfect for my use case.
Perturbing the vector
I can also add a small amount to a face’s embedding and see how it affects the output. In this image, the original face is in the center and the two axes correspond to adding values to different dimensions.

One thing this illustrates is that because the decoder is a simple transformation,
the shape of the face changes linearly too.
Interpolation
Alternatively, I can interpolate between two faces. I draw a straight line between the embeddings of the two faces, and then decode points on the line as faces.

Using Chernoff Faces on Embeddings
Now that I have a decoder that converts a 16-element vector into a face, I can use it to generate drawings based on the embeddings for subjects of books.
In that post, I created embeddings using PCA. I reran the notebook to create 16-element vectors of the embeddings.
Since these are 16-element vectors, I could feed them into the decoder as is. That isn’t a good idea though, because it’s outside of the space that the vector learned to decode. When I do this, it creates art.

As a rough way to match the distribution of points, I first encode valid faces to create a target distribution of the face embeddings. Then I assume both the source and target distributions are normally distributed. I scale and move the source distribution (the library subject embeddings) to match the target distribution. For this particular set of source embeddings, it helps to clip the outliers of the source distribution.
def convert_source_dist_to_target_normal(vector_from_source):
source_stdev = vector_from_source.std(axis=0)
source_mean = vector_from_source.mean(axis=0)
normal_source = (vector_from_source - source_mean)/source_stdev
# then line up with the new one
return normal_source * encoded_faces.std(axis=0) + encoded_faces.mean(axis=0)
def convert_source_dist_to_target_clipped_normal(vector_from_source):
source_stdev = vector_from_source.std(axis=0)
source_mean = vector_from_source.mean(axis=0)
normal_source = (vector_from_source - source_mean)/source_stdev
# first clip the very big extremes
# since it's already normalized, just use the number of stdevs
clip_number_stdevs = 3
normal_source = np.clip(normal_source, -clip_number_stdevs, clip_number_stdevs)
# then line up with the new one
return normal_source * encoded_faces.std(axis=0) + encoded_faces.mean(axis=0)
normal_catalog_vector = convert_source_dist_to_target_normal(raw_catalog_vectors)
catalog_vectors = convert_source_dist_to_target_clipped_normal(raw_catalog_vectors)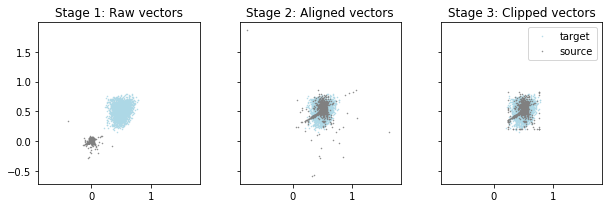
Chernoff faces for subjects related to ‘drama’
The following example selects several library catalog subjects that contain the string ‘drama’. Then it shows the face generated by the method above that corresponds to the embedding of that subject. It also shows a scatterplot of the first two dimensions of the original embedding, with a black x through the subject.

The plot shows a few features of Chernoff faces.
The scatter plot only shows two of the sixteen dimensions, while the face may use many dimensions. The black x’s look like they are in the same place for all plots, but the faces show additional differences and similarities. For example, I think “fathers and sons drama” looks more similar to “brothers and sisters drama” than to “human alien encounters drama”.
In addition, the face for “television melodrama” looks very different than the others.
However, there are also some issues. Some elements of the embedding may create outsized differences in the face, while others may result in unnoticeable differences. As it is currently implemented, I don’t have control over how much each dimension is used.
Random subjects
For fun, here’s a variety of faces corresponding to a random sample of subjects.

Attributions and other notes
- The dataset comes with the reference:
Interactive Facial Feature Localization Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang. ECCV2012
- And thanks for the encouragement, tips, and/or ideas from Simon Ignat, Xinming Wang, and Antreas Antoniou!