Illustration of max-pooling in NLP
This is another quick post derived from my thesis post. Two papers I read for my master’s thesis were Yoon Kim et al’s “Character-Aware Neural Language Models” and Jason Lee et al’s “Fully Character-Level Neural Machine Translation without Explicit Segmentation”. I created this diagram to explain the difference between how Kim and Lee use max-pooling. My thesis looked at using individual characters to understand a word, while Kim’s language modeling and Lee’s machine translation papers both involve the more data-intensive task of using individual characters to understand text.
Set up
Let’s say we have a few convolutional layers that act on characters in a word.
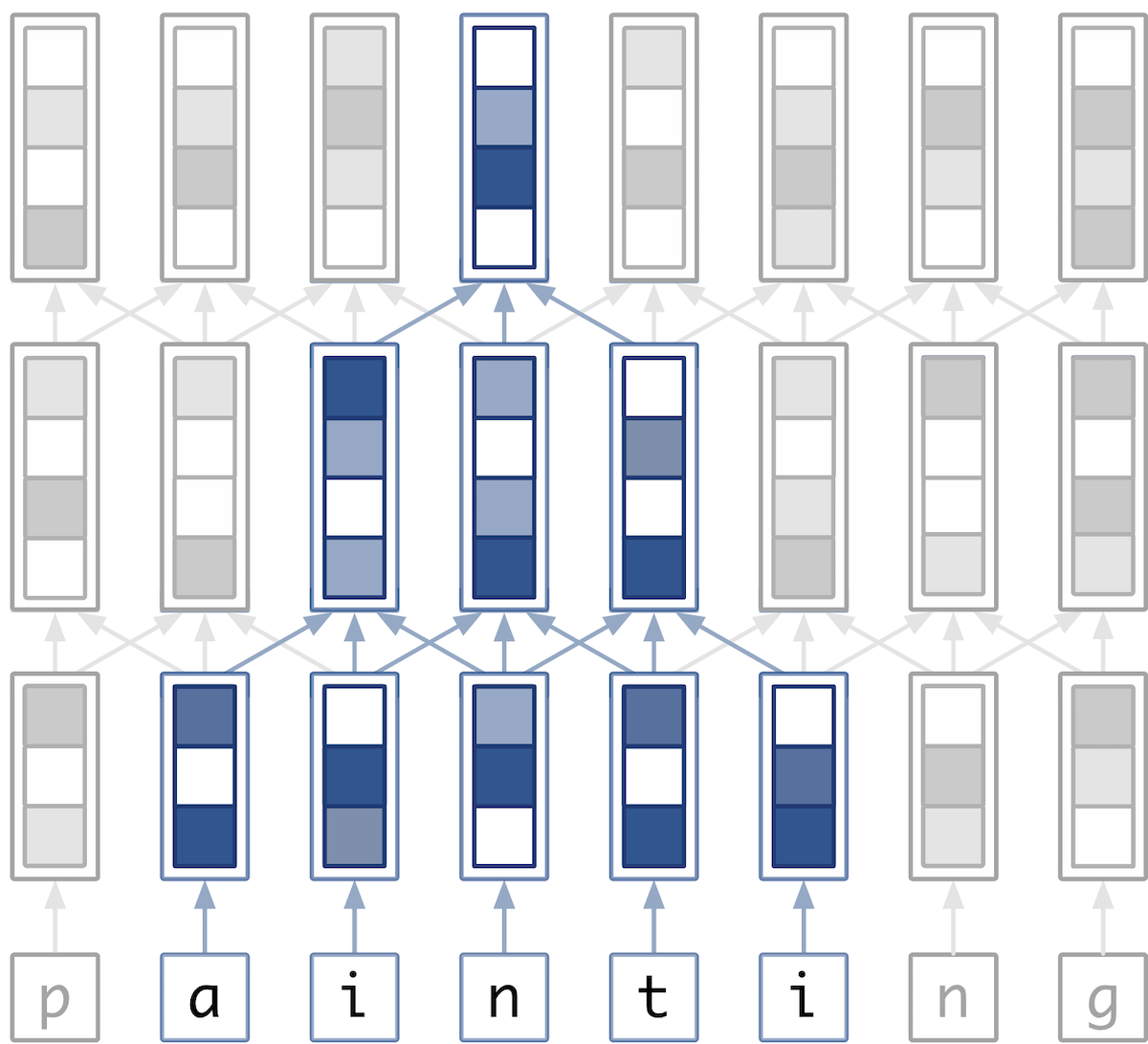
For example, these could be the embedding or encoding layer from a seq2seq model, or the last layer before classification. If the input is the word “painting,” a set of hypothetical convolutional layers that use padding could output 7 length-5 vectors (7 vectors because there are 7 letters in “painting.”)
Comparison of max-pooling
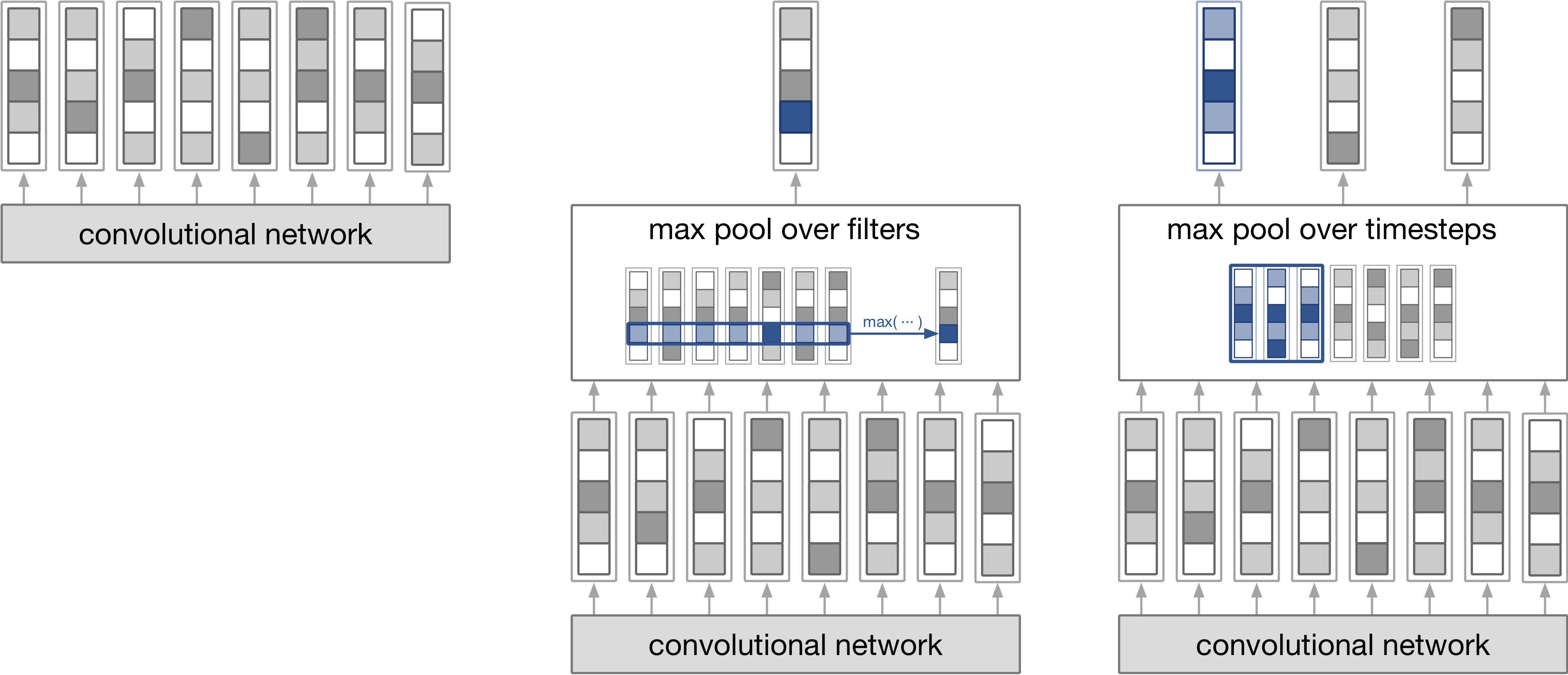
In the left image (1), the convolutional layers output could be used directly, which is what I do for my thesis.
In the center image (2), max-pooling over filters, such as Kim et al., results in a single length 5-vector for each word. The max-pooling chooses the max for each of the 5 slots over the 7 vectors.
In the right image (3), max pooling over timesteps, such as Lee et al., results in 3 length-5 vectors. Like the center image, it chooses the max for each slot of the vectors, but it only looks at a window of 3 vectors.
Observations
The output size of (1) and (3) depends on the length of the input.
One result is that only the output of (2) can be fed directly into a fully-connected layer. Max-pooling over filters is useful for creating classifiers.
The output of (2) and (3) reduces the size of the input. That is important for when there is a lot of data, such as in character-level language modeling or machine translation.